This is a guest post by Alex Rabinovich, Anindya Dasgupta, and Vijesh Chandran from Vanguard, Financial Advisor Services division, in partnership with AWS.
Vanguard stands as one of the world’s leading investment companies, serving more than 50 million investors globally. The company offers an extensive selection of low-cost mutual funds and ETFs with over 450 funds/ETFs along with comprehensive investment advice and related financial services. With a workforce of approximately 20,000 crew members, Vanguard has built its reputation on providing low-cost, high-quality investment solutions that help investors achieve their long-term financial goals.
Within this massive organization, Vanguard’s Financial Advisor Services (FAS) division stands as one of the most prominent B2B operations in the financial services industry. Operating at an extraordinary scale, FAS oversees a broad range and diverse range of assets through the intermediary channel while supporting a vast network of advisory firms and financial advisors across the country. This division delivers a full suite of investment products, model portfolios, research capabilities, and technology-driven support services designed to help financial advisors serve their clients more effectively.
The scale and complexity of FAS operations generate enormous amounts of data that require sophisticated analytics capabilities to drive business insights, regulatory compliance, and operational efficiency. To address this, Vanguard launched the FAS 360 initiative. This initiative aims to empower Financial Advisor Services (FAS) with a centralized cloud data warehouse that integrates both internal and external data sources into a unified, intelligent system.
By consolidating these use cases into a centralized system, FAS 360 enables consistent reporting and data-driven decision-making across Vanguard’s Financial Advisor Services division.
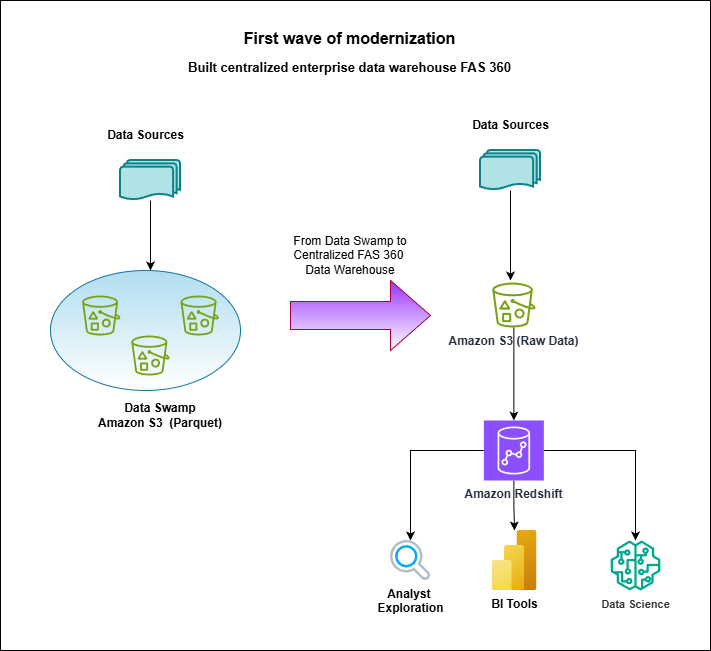
Vanguard’s first wave of modernization established FAS 360 as a centralized enterprise data warehouse, migrating from a fragmented “data swamp” of Parquet files on Amazon Simple Storage Service (Amazon S3) to a structured, unified system.
The following architecture diagram leverages Amazon S3 for raw data storage with Amazon Redshift serving as the core processing engine, providing integrated access for BI tools, analyst exploration, and data science workloads.
Here are the key benefits achieved with this architecture:
This centralized architecture successfully addressed the limitations of Vanguard’s previous approach, where data was scattered across individuals with limited governance, and established a foundation for their subsequent architectural evolution.
Vanguard FAS experienced remarkable growth in their data analytics requirements over a two-year period, demonstrating the rapid evolution of modern data needs:
Initial State:
Two Years Later:
This exponential growth reflected FAS’s increasing reliance on data-driven decision making across the business functions, from risk management and compliance to client service optimization and operational efficiency improvements.
As Vanguard FAS’s data environment expanded, their initial architecture, a single Amazon Redshift provisioned cluster with 2 nodes (ra3.4xlarge), began experiencing severe performance challenges that threatened business operations:
ETL performance issues:
End-user experience degradation:
Operational challenges:
These challenges were fundamentally limiting FAS’s ability to leverage their data assets effectively, impacting everything from daily operational reporting to strategic business analysis.
To address these critical challenges, Vanguard FAS implemented following multi-warehouse architecture that leverages the advanced data sharing capabilities of Amazon Redshift for workload isolation and independent scaling.
Producer – Amazon Redshift Provisioned Cluster
The central hub consists of the original Amazon Redshift provisioned cluster with RA3 nodes, optimized for consistent, predictable workloads:
Consumer – Amazon Redshift Serverless Workgroups
Multiple Amazon Redshift Serverless instances serve as specialized consumer endpoints which auto-scales compute resources based on demand:
The solution leverages the native data sharing capabilities of Amazon Redshift to enable secure connectivity between the producer and consumers instances. Consumer clusters can access live data from the producer without data movement, providing real-time access to the most current information available. This zero-copy sharing approach alleviates the need for data duplication or complex synchronization processes, helping reduce both storage costs and operational complexity.
The implementation of the multi-warehouse architecture delivered significant improvements across the key performance indicators:
Nightly ETL cycles now consistently complete before the 9 AM SLA, eliminating the previous SLA failures that disrupted business operations and ensuring fresh data is available for morning business activities. Dashboards and reports now reflect the most current data available, providing teams with up-to-date insights for decision-making.
The new architecture removed the restrictive 10-minute query timeout that previously prevented deep ad hoc exploratory queries. Analysts can now run complex analytical workloads exceeding 30 minutes in a fully isolated environment without impacting other users or ETL processes. This change, combined with significantly faster query response times, has led to higher analyst satisfaction and productivity across the team.
The architecture introduced a dedicated “Data Lab” environment where analysts have write access to experiment with data using CREATE TABLE AS SELECT (CTAS) commands. Each workload type can now scale independently based on demand, with different consumer clusters optimized for specific use cases, enabling more sophisticated analytical approaches.
The separation of workloads enabled efficient utilization of compute resources across different patterns, leading to better cost control through appropriate sizing, serverless pay-as-you-go pricing, and reserved instance usage. The cleaner separation of concerns between ETL and analytics workloads has simplified overall management of the data platform.
As Vanguard’s data environment matured and their success with the multi-warehouse architecture enabled broader adoption across the organization, they recognized an opportunity to evolve their architecture to match their organizational growth. The expanding portfolio of data products and increasing number of teams leveraging the system created new opportunities for innovation.
As Vanguard’s data environment grew, three key challenges emerged:
Vanguard’s decision to adopt Data Mesh was driven by the need to:
This evolution supports Vanguard’s ability to scale organizationally while building on the technical foundation and operational excellence achieved with their multi-warehouse architecture. Building on the success of their Amazon Redshift multi-warehouse implementation, Vanguard FAS is now exploring on the next phase of their data architecture evolution, implementing following data mesh approach.
This new data mesh architecture has several key components that work together to enable scalable, domain-oriented data management.
Vanguard is establishing distinct data domains aligned with business functions and assigning dedicated data stewards to each domain for clear ownership and accountability. This strategy shifts from centralized data management to a decentralized model where data ownership and responsibility can be distributed across business domains, enabling teams closer to the data to make informed decisions about their domain-specific needs.
The new architecture isolates domain-specific data loads to separate compute endpoints and creates independent data processing pipelines for each domain. This approach helps reduce cross-domain dependencies and conflicts that previously slowed development cycles, allowing teams to iterate and deploy changes without waiting for coordination across the entire organization.
Vanguard is curating data products on the data lake using Apache Iceberg format and leveraging AWS Glue for metrics computation and data lake integration. This approach treats data as products with defined SLAs and quality metrics, helping facilitate reliable, high-quality data delivery that downstream consumers can depend on with confidence.
The implementation enables domain teams to manage their complete data product lifecycle independently while maintaining enterprise governance standards. Vanguard provides comprehensive tools and systems for independent data management, allowing teams to innovate quickly without compromising data quality or security, ultimately accelerating time-to-insight across the organization.This evolution represents a natural progression from centralized data warehouse to multi-warehouse architecture, and finally to a fully distributed, domain-oriented data mesh that can scale with Vanguard’s continued growth.
Vanguard Financial Advisor Services’ journey demonstrates that scaling analytics is no longer about scaling a single warehouse bigger, but about architecting for workload isolation, independent scaling, and organizational growth.
By evolving from a single 2-node RA3 provisioned cluster to a multi-warehouse architecture using Amazon Redshift Serverless and Provisioned, Vanguard achieved measurable, production-grade outcomes:
Critically, these gains were not achieved by over-provisioning compute, but by right-sizing and specializing compute per workload, reserving capacity where demand was predictable (ETL) and using Amazon Redshift Serverless auto-scaling where demand was bursty (BI and ad-hoc analysis).
As Vanguard now progresses toward a domain-oriented data mesh, their experience reinforces a key lesson: Multi-warehouse architecture is a foundational enabler for organizational scale, data product ownership, and autonomous analytics.For organizations experiencing exciting growth in their data analytics requirements, Vanguard’s approach showcases the tremendous possibilities that await. With the right architecture and the help of AWS services, organizations can transform their data infrastructure to achieve remarkable improvements in performance, significant cost reductions, and unlock powerful new analytical capabilities that accelerate business value creation.
AWS encourages you to connect with your AWS Account Team to engage an AWS analytics specialist who can provide expert architectural guidance and tailored recommendations to help you achieve your data transformation goals.
© 2026 The Vanguard Group, Inc. and Amazon Web Services, Inc. All rights reserved. This material is provided for informational purposes only and is not intended to be investment advice or a recommendation to take any particular investment action.
Alex is a Director of Data Engineering at Vanguard, aligned to Financial Advisory Services division. In this role, he leads large‑scale data engineering platforms and modernization initiatives, focusing on building reliable, scalable, and high‑performance data systems in the AWS cloud.
Anindya is a solutions architect in Vanguard’s Financial Advisor Services Technology division. He has over 25 years of experience building enterprise technology solutions to address complex business challenges. His work focuses on architecting and designing scalable, cloud‑native and data‑driven systems, with hands‑on contributions across application development, system integration, and proof‑of‑concept initiatives.
Vijesh is Head of Solution Design, overseeing the architecture and design of enterprise technology solutions that support critical business outcomes. His background spans data architecture on cloud‑native platforms, and data‑driven systems, with a strong focus on aligning technology design to business strategy. He plays a hands‑on role in guiding solution direction, integration patterns, and proof‑of‑concept initiatives.
Raks is a Senior Analytics Specialist Solutions Architect at AWS based out of Pennsylvania. He helps customers across varying industries and regions architect data analytics solutions at scale on the AWS platform. Outside of work, he likes exploring new travel and food destinations and spending quality time with his family.
Poulomi is a Senior Analytics Solutions Architect with AWS. She is passionate about helping customers build cloud-based analytics solutions to solve their business problems. Outside of work, she likes travelling and spending time with her family.







